
1. Introduction
Kafka is not really a new product on the software market. It has been some 10 years since LinkedIn released it. Although by that time there had already been available products with similar functionality on the market, the open source code and broad support from the expert community, particularly through Apache Incubator, allowed it to quickly get on its feet, and later to seriously compete with alternative solutions.Conventionally, Kafka has been viewed as a set of data receipt and transfer services, which allow data to be accumulated, stored and retrieved with extremely low latency and high throughput. It has been a kind of reliable and fast (and actually the most popular at the moment) message broker, in high demand in many ETL processes. Kafka key advantages and capabilities have been repeatedly discussed across community including wide range of Internet resources. We are not going to recap Kafka's merits here, just take a look at the list of organizations that have chosen this product as a basic tool for their solutions. Refer to the official website, which says that Kafka is currently being used by thousands of companies, including more than 60% of the Fortune 100 companies. These include Box, Goldman Sachs, Target, Cisco, Intuit, and others [1].
Today, Apache Kafka is often recognized, with good reason, as the best product on the data transfer system market. However, Kafka is not only appealing as a message broker. It is also of enormous value because many specific software products have emerged and evolved out of it, allowing Kafka to greatly expand its capabilities. And this, in turn, allows it to progress steadily into new areas of the IT market.
As a rule, Kafka is built into the ETL process (ETL is an abbreviation for Extract, Transform, Load), which, in the simplest case, comprises the following steps:
1 - extraction of data from the source;
2 - cleaning and transformation of data;
3 - loading into the target system.
Kafka's tasks were focused on data delivery within the ETL process. Is there any possibility to extend Kafka (broadly speaking, the entire ecosystem that has sprung up around Kafka) towards solving ETL tasks? Yes, as items 1 and 3 are nowadays quite successfully addressed by means of so-called Kafka connectors. We shall dwell on it briefly here, since all the necessary information can be found on the relevant websites [2, 3].
Kafka Connect is a tool for scalable and reliable data streaming between Apache Kafka and other data systems. The process of extracting data from external systems can be implemented using the Source Kafka Connect engine, which can both obtain entire databases and ingest metrics from all your application servers into Kafka topics. Another type of connector, Sink Kafka Connect, is designed to transfer data from Kafka to secondary stores, such as Elasticsearch, Hadoop or other databases, for subsequent work.
By now, a fair number of connectors of all types have been developed, which allows for an interaction procedure for obtaining data from a wide range of sources (the same is true for data storage on a selected platform). One of the backbone sites offering such plugins [4] features several hundred connectors for almost all popular data sources.
2. Data transformation
As mentioned above, the Kafka ecosystem is currently on its way to a full-fledged ETL tool. In other words, you can successfully build and develop comprehensive ETL solutions based on the Kafka ecosystem alone. Yet, we have not yet mentioned the core part of the ETL process - data transformation. Since business requirements are always unique, there are no ready-made transformation solutions. In each case, it is a separate task that calls for an individual approach. In this article we would like to focus on one of these tools, which has been booming in recent years, namely ksqlDB.ksqlDB is a database constructed on the data stored in Kafka [5]. Due to the ksqlDB platform, Apache Kafka offers processing, creating and storing data streams through simple and straightforward SQL queries. ksqlDB enables you to perform all kinds of big data streaming analytics: filtering, connection, aggregation, creating materialized views, converting and mapping event streams using standard SQL query tools. It allows analysts and developers to extensively use this event streaming platform in a variety of tasks.
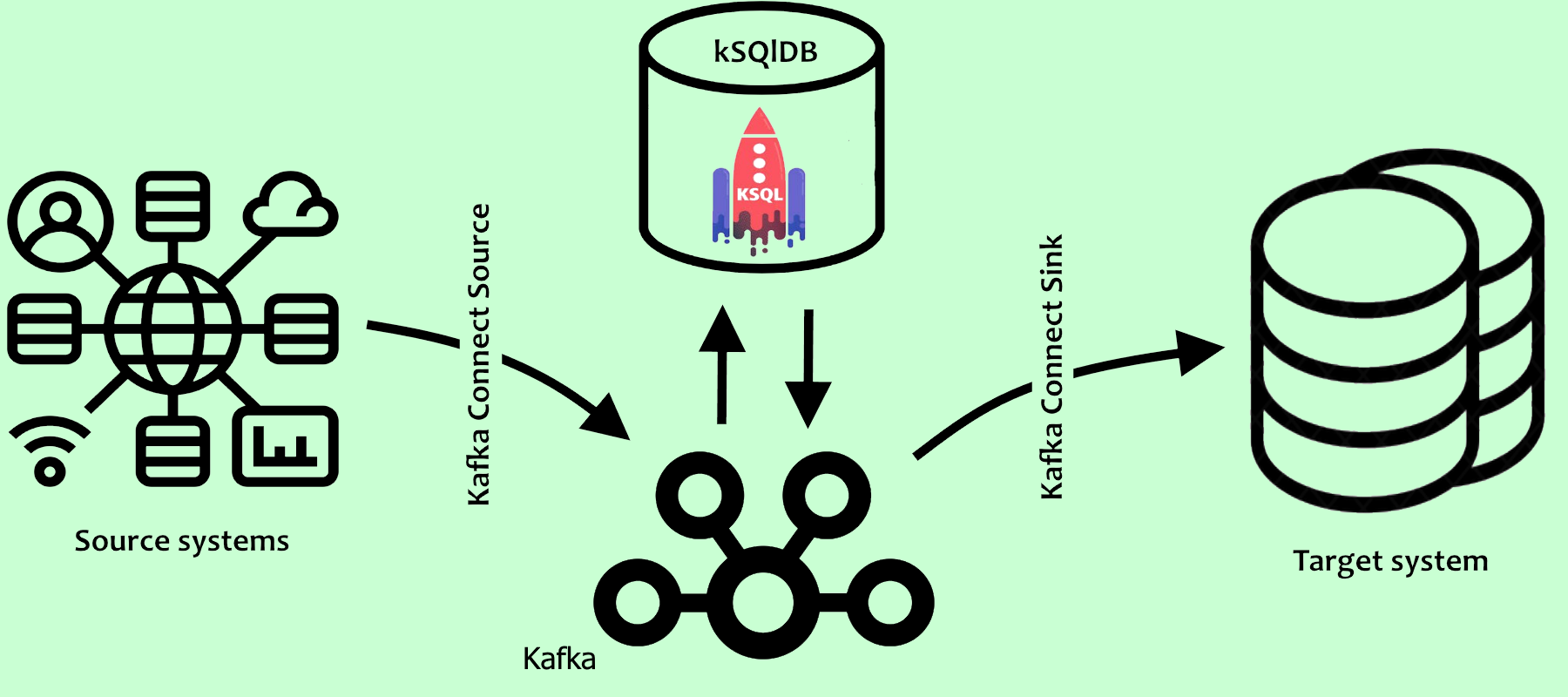
Let's take a look at some basic ksqlDB constructs.
2.1 Streams in ksqlDB
Streams are objects constructed over Kafka topics, in which data is stored. Streams represent data in motion; new incoming data do not change any of the existing entries, but are only added to the current stream. Thus, data in the stream always remain unchanged.
Here's a simple example of flow construction.
The very first thing we have to do is to create a Kafka topic. For this, let's use the standard command-line utility kafka_topics.sh:
./bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic tpk_persons
Now, using another tool - kafka-console-producer - let's upload the test data to the newly created topic:
./bin/kafka-console-producer.sh
--broker-list localhost:9092 \
--topic tpk_persons
Enter JSON data in a pop-up console window. For example:
{"ID":1,"NAME":"JONH,SMITH","AGE":25}
{"ID":2,"NAME":"JOHN,DOE","AGE":27}
{"ID":3,"NAME":"DON,JACKSON","AGE":29}
We will need the ksqlDB Cli tool to create a stream. Suppose a ksqldb server is installed on your host.
Running the server:
sudo /usr/bin/ksql-server-start /etc/ksqldb/ksql-server.properties
Then you can start the client-based application:
/usr/bin/ksql http://0.0.0.0:8088
Copyright 2017-2021 Confluent Inc.
CLI v0.20.0, Server v0.20.0 located at http://0.0.0.0:8088
Server Status: RUNNING
Let's check for the data in the appropriate topic tpk_persons using the ksqlDB Cli application. To do this, just run the command print tpk_persons. But to make sure that our queries read the data from the beginning of the Kafka topic, let us run the following command before that:
SET 'auto.offset.reset' = 'earliest';
The result is shown below:
ksql> print tpk_persons;
Key format: ¯\_(ツ)_/¯ - no data processed
Value format: JSON or KAFKA_STRING
rowtime: 2021/10/31 15:19:24.922 Z, key: <null>, value: {"ID":1,"NAME":"JONH,SMITH","AGE":25}, partition: 0
rowtime: 2021/10/31 15:19:25.019 Z, key: <null>, value: {"ID":2,"NAME":"JONH,DOE","AGE":27}, partition: 0
rowtime: 2021/10/31 15:19:25.019 Z, key: <null>, value: {"ID":3,"NAME":"DON,JACKSON,"AGE":29}, partition: 0
Since the format has been selected, the stream will also be created indicating the appropriate format
CREATE OR REPLACE STREAM str_persons (
id BIGINT
, name VARCHAR
, age INT
) WITH (
KAFKA_TOPIC = 'tpk_persons'
, VALUE_FORMAT = 'JSON'
);
Now ksqlDB enables you to refer to the stream as a table structure. And the great thing is that the language we will use to work with data is virtually standard SQL, and this makes our work much easier.
ksql> SELECT * FROM str_persons EMIT CHANGES;
+---------+----------------------+------+
|ID |NAME |AGE |
+---------+----------------------+------+
|1 |JOHN,SMITH |25 |
|2 |JOHN,DOE |27 |
|3 |DON,JACKSON |29 |
As mentioned above, you can't modify data, but you can add it. So, running 'insert" in the stream written by sql standards is a perfectly valid procedure.
INSERT INTO str_persons (id, name, age) VALUES (4, 'JONH,SMITH', 32);
We would like to point out that the commonly used sql syntax is not just good for displaying data, but is a very powerful tool for converting such data. We are not going to describe some of querying syntax specifics, as this would clutter up the presentation and boil it down to quoting documentation. You can always go to the website [6] and find all the answers you need.
Hopefully, simple JSON types are understandable, but what about complex constructs with attachments and repetitions? After all, JSON may not be as simple as the example above. Everything is fine here too, ksqlDB allows to solve this problem as well. Now let's show how it can be done by creating a new topic tpk_workers and writing a more complicated JSON in it:
{"WOKERS":[
{"ID":1,"NAME":"JONH,SMITH","AGE":25}
, {"ID":2,"NAME":"JONH,DOE","AGE":27}
, {"ID":3,"NAME":"DON,JACKSON","AGE":29}
]} *]} *
(*a single-line entry is needed when adding to the topic, formatting is used here as an example)
Let's create a stream in ksqlDB, just to fit its structure:
CREATE STREAM str_wokers (
WOKERS ARRAY<
STRUCT<
id BIGINT
, name VARCHAR
, age INT
>>)
WITH (KAFKA_TOPIC='tpk_wokers',
VALUE_FORMAT='JSON'
);
If the number of attachments is known beforehand, you can expand the answer by columns:
SELECT WOKERS[1]->id AS id1, WOKERS[1]->name AS name1, WOKERS[1]->age AS age1
, WOKERS[2]->id AS id2, WOKERS[2]->name AS name2, WOKERS[2]->age AS age2
, WOKERS[3]->id AS id3, WOKERS[3]->name AS name3, WOKERS[3]->age AS age3
FROM str_wokers EMIT CHANGES;
+---+-----------+----+---+-----------+----+---+------------+----+---------------------------+---------+
|ID1|NAME1 |AGE1|ID2|NAME2 |AGE2|ID3|NAME3 |AGE3|
+---+-----------+----+---+-----------+----+---+------------+----+---------------------------+----------+
|1 |JOHN,SMITH|25 |2 |JONH,DOE|27 |3 |DON,JACKSON|29 |
Or build everything into a single structure:
SELECT EXPLODE(WOKERS)->id AS id
, SPLIT(EXPLODE(WOKERS)->name, ',')[1] AS first_name
, SPLIT(EXPLODE(WOKERS)->name, ',')[2] AS last_name
, EXPLODE(WOKERS)->age AS age
FROM str_wokers EMIT CHANGES;
+----+-----------+----------+-------------+-------+
|ID |FIRST_NAME |LAST_NAME |AGE |
+----+-----------+----------+-------------+-------+
|1 |JONH |SMITH |25 |
|2 |JONH |DOE |27 |
|3 |DON |JACKSON |29 |
2.2 Data transformation in SQL queries
ksqlDB offers a fairly advanced SQL syntax, which enables you to convert, filter and aggregate data in streams. Now let us consider the following stream query:SELECT '<id>' + CAST(id AS VARCHAR) + '</id>'
+ '<first_name>' + split(name, ',')[1] + '</first_name>'
+ '<last_name>' + split(name, ',')[2] + '</last_name>'
+ '<age>' + CAST(age AS VARCHAR) + '</age>'
+ '<rowtime>' + CAST(ROWTIME AS VARCHAR) + '</rowtime>'as xml
FROM str_persons
WHERE age < 30
EMIT CHANGES;
This is an example of concatenation of text values, which essentially allows you to switch to XML format by appending the appropriate tags to each value obtained. We would like to draw more attention to the ROWTIME field. This is a system column that ksqlDB reserves to keep track of the event time (here the time appears in unix format). ROWTIME allows us to see when the data were entered into Kafka.
+---------------------------------------------------------+
|XML
+---------------------------------------------------------+ +---------------------------------------------------------+
|<id>1</id><first_name>IVAN</first_name><last_name>SMITH</last_name><age>25</age>
<rowtime>1635693564922</rowtime>|
|<id>2</id><first_name>PETR</first_name><last_name>DOE</last_name><age>27</age>
<rowtime>1635693565019</rowtime>|
|<id>3</id><first_name>SIDR</first_name><last_name>JACKSON</last_name><age>29</age>
<rowtime>1635693565019</rowtime>|
Aggregate functions can also be used in queries, but here (ksqlDb) always requires a GROUP BY clause. And if the output has show only the fields that are aggregated, the GROUP BY clause is also obligatory, although it looks illogical. This contradiction can be avoided in a fairly simple way:
SELECT '<max_age>' + CAST(max(age) AS VARCHAR) + '</max_age>' as max_age
FROM str_persons
GROUP BY 0
EMIT CHANGES;
+---------------------+
|MAX_AGE
+---------------------+
|<max_age>32</max_age>
Remember that the input data were in JSON format, but the result can be easily represented both in XML and CSV formats.
2.3 Saving the obtained results in a separate topic
We have shown previously that streams in ksqlDB can be created based on Kafka topics. But can we transfer already converted data to Kafka? We wrote a complex SELECT Query where we executed all the transformations we needed, and now we want to save the resulting query into a separate topic. So, we are going to use the following lines to do this:CREATE OR REPLACE STREAM str_jnew_persons
WITH (KAFKA_TOPIC='tpk_jnew_persons', VALUE_FORMAT='JSON')
AS SELECT id
, split(name, ',')[1] AS first_name
, split(name, ',')[2] AS last_name
, age
, TIMESTAMPTOSTRING(ROWTIME,'yyyy-MM-dd HH:mm:ss','Europe/Middle East') AS ts
FROM str_persons
WHERE age < 30
;
Here we would like to draw attention to three features:
1. When creating a stream, a new service word "FROM" is used, because in this case we obtain data from another stream;
2. The Kafka topic tpk_jnew_persons is not a source here, but a data sink;
3. Having created a new str_jnew_persons stream, we implicitly created a consumer whose task is to transfer data to the new tpk_jnew_persons topic. In other words, when we add data to the tpk_persons topic, we automatically activate a mechanism that converts input values according to the query and transfers them to the tpk_jnew_persons topic.
Fetching data from str_jnew_persons stream shows that all transformations have been successfully completed and the table structure has the exact number and contents of fields that was required by the query:
SELECT * FROM str_jnew_persons EMIT CHANGES;
+---+-----------+----------+----+--------------------+
|ID |FIRST_NAME |LAST_NAME |AGE |TS |
+---+-----------+----------+----+--------------------+
|1 |JOHN |SMITH |25 |2021-11-02 19:10:41 |
|2 |JONH |DOE |27 |2021-11-02 19:10:49 |
|3 |DON |JACKSON |29 |2021-11-02 19:10:57 |
Now let's check the content of the tpk_jnew_persons topic. To do this, let's use the standard command-line utility kafka-console-consumer.sh:
./bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic tpk_jnew_persons \
--from-beginning
We will obtain the following result:
{"ID":1,"FIRST_NAME":"JOHN","LAST_NAME":"SMITH","AGE":100,"TS":"2021-11-02 19:09:01"}
{"ID":1,"FIRST_NAME":"JONH","LAST_NAME":"DOE","AGE":25,"TS":"2021-11-02 19:10:41"}
{"ID":2,"FIRST_NAME":"DON","LAST_NAME":"JACKSON","AGE":27,"TS":"2021-11-02 19:10:49"}
{"ID":3,"FIRST_NAME":"DON","LAST_NAME":"JACKSON","AGE":29,"TS":"2021-11-02 19:10:57"}
By forwarding the data to a new topic, we give any software product access to it and retrieve the data already converted (cleaned, aggregated).
2.4 Transforming data formats in ksqlDB
In chapter 2.2, we basically executed conversions that extract data from the JSON format and created something resembling XML. The very availability of this feature is a big advantage, which offers us sql for data conversion. However, data transformation is not exhausted by this possibility alone.Data transformation often means converting to another format as well. It's one thing to transfer data from peripherals via HTTP, where json or xml are appropriate formats, but it's quite another thing to store data in those formats. True, json or xml formats are supported as a distinct type in most modern databases, but storing data in this manner is not the best option (difficulties in querying, data consistency issues, productivity losses, etc.).
Let's see what ksqlDB has to offer when it comes to format conversion.
Documentation shows that ksqlDB supports a number of serialization formats. Here are just a few of them: DELIMITED, JSON, AVRO, PROTOBUF. The serialization format is specified when the stream is being created. For example, when creating the stream str_persons, we indicated the JSON format (VALUE_FORMAT = 'JSON'). Is it possible to convert data coming in one format, say JSON, to AVRO format by means of ksqlDB? ksqlDB alone, alas, will not be enough here. Nevertheless, we will show you how it can be done.
We will need another Kafka ecosystem product, Schema Registry, to solve this task. This product is a part of Confluent Platform [7] and, therefore, can be installed as part of Confluent Platform. But if you already have all the necessary products on your host, you can install only this product to install just Schema Registry.
yum install confluent-schema-registry –y
As we can see in the documentation to date, Schema Registry supports Avro, JSON, JSON Schema and Protobuf formats. This software provides a RESTful interface for storing and retrieving schemas (a description of how an atomic unit - say, a row in Avro format - is arranged).
All types, conversions to (or from) which Schema Registry supports can be viewed directly in your browser. The 'ksql.schema.registry.url' parameter should be set to 'http://localhost:8081' in the ksql-server.properties settings file.

We need to register an AVRO schema for our dataset so that we can take advantage of Schema Registry. It is easy to see that in our case the schema will be as follows:
{
"type": "record",
"name": "Persons",
"fields": [{"name": "Id", "type": "long"},
{"name": "name", "type": "string"},
{"name": "age", "type": "int"},
{"name": "ts", "type": "string"}
]
}
Now all you have to do is run REST query to the server to register the new schema. You can do this using the standard 'curl' utility as follows:
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \
-d '{"schema": "avro_schema"}' \
http://localhost:8081/subjects/tpk_anew_persons/versions
Here the avro_schema parameter should be replaced by the schema above (don't forget to escape double quotes), while the tpk_anew_persons is kafka topic, where we actually plan to load data in AVRO format.
Once you have completed the registration process, you can see the schema at http://localhost:8081/schemas/
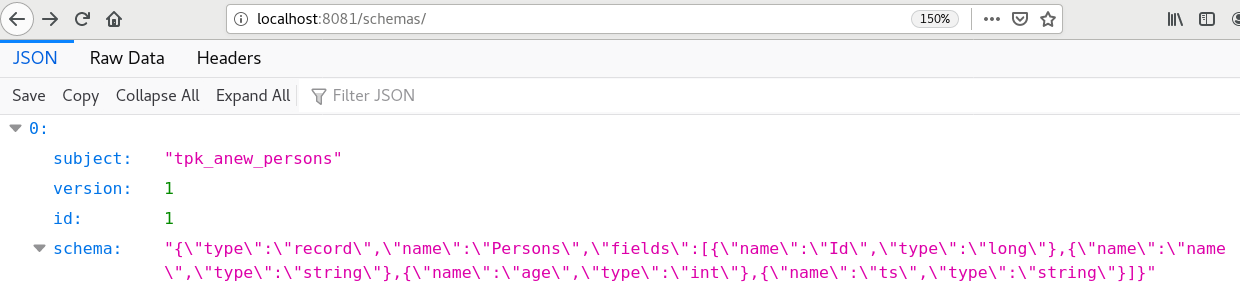
And only now can we create a stream with an appropriate format: it will be constructed on the new Kafka topic - tpk_anew_persons. See below for the syntax to create the required stream for the ksqlDb Cli command-line tool:
CREATE OR REPLACE STREAM str_anew_persons
WITH (KAFKA_TOPIC='tpk_anew_persons', VALUE_FORMAT='AVRO')
AS SELECT id
, split(name, ',')[1] AS first_name
, split(name, ',')[2] AS last_name
, age
, TIMESTAMPTOSTRING(ROWTIME,'yyyy-MM-dd HH:mm:ss','Europe/Middle East') AS ts
FROM str_persons
WHERE age < 30
;
However, if you want to view the contents of the tpk_anew_persons topic, you now need a different kind of consumer - kafka-avro-console-consumer (installed with the Schema Registry package). Let's check out the result:
/usr/bin/kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--topic tpk_anew_persons \
--from-beginning \
--property schema.registry.url=http://localhost:8081
{"ID":{"long":1},"FIRST_NAME":{"string":"JOHN"},"LAST_NAME":{"string":"SMITH"},"AGE":{"int":25},"TS":{"string":"2021-11-03 00:46:23"}}
{"ID":{"long":2},"FIRST_NAME":{"string":"JONH"},"LAST_NAME":{"string":"DOE"},"AGE":{"int":27},"TS":{"string":"2021-11-03 00:47:03"}}
{"ID":{"long":3},"FIRST_NAME":{"string":"DON"},"LAST_NAME":{"string":"JACKSON"},"AGE":{"int":29},"TS":{"string":"2021-11-03 00:58:28"}}
To put it another way, although format conversion is not very versatile (the list of supported formats is, unfortunately, not extensive yet), but it is quite a good solution.
2.5 Lambda and Kappa architectures from ksqlDb perspective
Despite all the advantages of lambda architecture, the major drawback of this approach to designing Big Data systems is its complexity, because of database logic duplication in "cold" and "hot" paths. Let's examine what a lambda architecture could look like when it comes to writing queries to Kafka. Here we have no separation into two paths, but the duplication of query logic persists. The fast layer no longer needs a separate storage because fast data is in Kafka already. The issue of strict data partitioning remains to be solved, otherwise we run a risk of accounting for part of the data twice. Suppose that Kafka topics are configured to store them for more than a day. Then the data stored in the target base (see Figure 1) will be considered cold. Thus, all our database queries should take into account the relevant condition (until "today's" data).Meanwhile, you can get fast data directly from Kafka by also adding an appropriate condition to the query (today's data only). On the other hand, topics can be set up so that the information received is not deleted at all. It's up to you as to how good this approach is, but in this case a complex task is "degraded" to the level of a simple one, and we get a Kappa architecture, where there is no separation into hot and cold paths. The full amount of data here is stored in Kafka, and the entire data query logic is implemented in ksqlDb.
3. Conclusion
Transformation process is one of the ETL cornerstones. The universe of big data has a wealth of applications of all kinds that have been more or less successful in solving this problem. Each has its own strengths and vulnerabilities, and not all can provide high reliability and processability of big data streams in a short time. Thus, Big Data transformation tools often work in conjunction with Kafka. Kafka is quite good for such tasks, but usually as a simple message broker.With the advent and development of tools such as CDC (Change Data Capture) and all kinds of Kafka connectors, the state of affairs has been evolving. The product ecosystem that has evolved out of Kafka is now able to fetch all data changes directly from the database and distribute new data in relevant Kafka topics. Even this version has already greatly addressed the problem of replication ("old" data backup + Kafka for "new" data), which means that complex stand-by systems, which are often built to improve reliability, can be replaced by Kafka to some extent. Moreover, the stand-by option in some cases means doubling licenses, i.e. additional financial costs. However, on the other hand, stand-by not only means reliability, but also a possibility of complex reporting on the auxiliary server, with no load on the host server. So, there was one more step to take: configuring Kafka to handle data streams as with regular tables. That is, learning to get only the information you need for the report, and to do this you had to configure Kafka to read the standard structured query language - SQL.
With the launch of ksqlDb, the issues of reporting and data transformation can be solved with a high degree of efficiency, and the software solutions previously used to solve such problems (sometimes very expensive, especially as compared to free, open-source ksqlDb) will not seem so appealing anymore.
KsqlDB implements many constructs that have long been a standard for almost any database. These include tables constructed on topics, and table and stream joins (inner, left and full joins are fully implemented). Besides, the options of sql modifications and data enrichment only increase from version to version. Of course, the set of SQL statements that are now supplied as the standard ksqlDb package may not impress people who have been working with databases for a long time and are used to a variety of sql syntax. Nevertheless, the possibilities already available coupled with the rather rapid evolution in this field allow us to say that ksqlDB offers really wide possibilities for data conversion, and they will only keep on growing. The possibility to individually add missing functions through the existing UDF mechanism, which makes it possible to solve a large class of ETL tasks by ksqlDB means, should be attributed to the system's advantages.
Kafka, and the entire ecosystem of products that has evolved out of it, has come a long way from just another message broker to a very mature toolset that can handle a wide variety of tasks. Time will tell if Kafka+ksqlDB can fully replace the database [8, 9]. But it is already quite obvious that a range of tasks can be solved without target-database. After all, you already have everything you need for work: a fast and reliable data storage system (the Kafka itself), and sampling practically any data by means of ksqlDb. Of course, it all comes to a specific task, and Kafka+ksqlDB is not a complete replacement for a DBMS. But if you use Kafka, you may want to take a closer look at ksqlDb: it may be just the right tool for your task.
References:
[1] https://kafka.apache.org/powered-by/
[2] https://docs.ksqldb.io/en/latest/concepts/connectors/
[3] https://www.confluent.io/product/confluent-connectors/
[4] https://www.confluent.io/hub/
[5] https://ksqldb.io/
[6] https://docs.ksqldb.io/
[7] https://docs.confluent.io/platform/current/release-notes/index.html
[8] https://dzone.com/articles/is-apache-kafka-a-database-the-2020-update
[9] https://davidxiang.com/2021/01/10/kafka-as-a-database/